কিছুদিন আগে একটা আর্টিকেল লিখেছিলাম ব্লুম ফিল্টার নিয়ে। কাউন্ট-মিন স্কেচ অনেকটা সেরকমই একটা প্রোবালিস্টিক ডাটা স্ট্রাকচার। এরা কাজও করে অনেকটা একইভাবে যদিও কাজের ধরণ এবং ব্যবহার সম্পূর্ণ আলাদা। অ্যালগরিদম জানা থাকলে কম রিসোর্স খরচ করেই কিভাবে অনেক ডাটা হ্যান্ডেল করা যায় তার একটা চমৎকার উদাহরণ কাউন্ট-মিন স্কেচ। ব্লুম ফিল্টার কিভাবে কাজ করে সেটা না জানলেও তুমি এই লেখাটা বুঝতে পারবে।
ধরো তোমাকে একটা স্ট্রিং এর অ্যারের দেয়া আছে। তোমাকে বলতে হবে অ্যারেতে কোন স্ট্রিং কতবার আছে, অর্থাৎ স্ট্রিংগুলোর ফ্রিকোয়ন্সি বের করতে হবে।
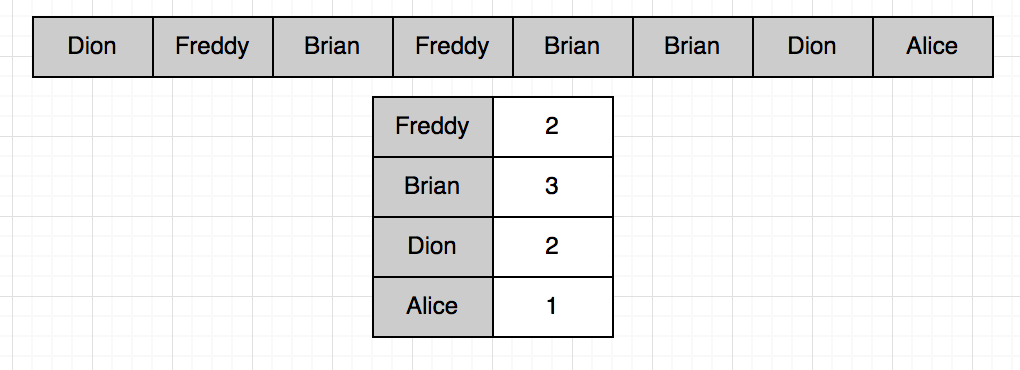 উপরের ছবিতে একটা উদাহরণ দেখানো হয়েছে। ইনপুট অ্যারেতে ৮টা স্ট্রিং দেয়া আছে, কোন স্ট্রিং কয়বার আছে সেটা টেবিলে দেখানো হয়েছে।
উপরের ছবিতে একটা উদাহরণ দেখানো হয়েছে। ইনপুট অ্যারেতে ৮টা স্ট্রিং দেয়া আছে, কোন স্ট্রিং কয়বার আছে সেটা টেবিলে দেখানো হয়েছে।
এটা খুব সহজ একটা প্রবলেম, তুমি একটা সাধারণ হ্যাশম্যাপ ব্যবহার করে সহজেই ফ্রিকুয়েন্সি বের করতে পারো। হ্যাশম্যাপের স্পেস কমপ্লেক্সিটি O(n) এবং হ্যাশম্যাপে নতুন ভ্যালু যোগ করা বা ভ্যালু খুজে বের করার এভারেজ কমপ্লেক্সিটি O(1)।
সলিউশনটা বেশ ভালো, আমাদের অতিরিক্ত জায়গাও খরচ হচ্ছে না, খুবই দ্রুত ফ্রিকুয়েন্সি বের করে ফেলতে পারছি, তাই না? এখন চিন্তা করো তোমার গুগলের মতো একটা সার্চ ইঞ্জিন আছে। তুমি সেখানে কোন শব্দ কতবার সার্চ করা হচ্ছে বের করতে চাও। যখনই কোনো ইউজার কোনো শব্দ সার্চ করে, তুমি আগের মতোই হ্যাশম্যাপে সে শব্দটির ফ্রিকুয়েন্সি বাড়িয়ে দিতে পারো। তুমি তোমার ইনকামিং ডাটাকে কল্পনা করতে পারো ডাটার একটা স্ট্রিম হিসাবে, একটা একটা করে শব্দ স্ট্রিম দিয়ে আসছে, তুমি হ্যাশম্যাপে সেটাকে প্রসেস করে রেখে দিচ্ছো।

সমস্যা হলো প্রতিদিন প্রায় ১গিগাবাইট ডাটা তোমার স্ট্রিম দিয়ে আসে, মাসে প্রায় ৩০গিগাবাইট ডাটা। এর মধ্যে যদি মাত্র ৫০% বা ১৫ গিগাবাইট ডাটাও ইউনিক হয়, তোমার মাসে ১৫ গিগাবাইট সাইজের হ্যাশম্যাপ লাগবে ফ্রিকুয়েন্সি ক্যালকুলেট করতে।
এরকম বিশাল ডাটা হ্যান্ডেল করা খুব একটা সহজ না। তুমি সাধারণ ডেটাবেসে এই ডাটা রাখতে পারবে না, তোমার কোনো ধরণের ডিস্ট্রিবিউটেড সিস্টেম ব্যবহার করতে হবে। তুমি যদি ক্লাউড সার্ভিস ব্যবহার করো তাহলে বিলও আসবে বিশাল আকারের।
লিনিয়ার স্পেস কমপ্লেক্সিটি এখন আর খুব একটা ভালো মনে হচ্ছে না। সিস্টেম স্কেলিং করার সময় আমাদেরকে প্রায় সময়ই কিছু ট্রেড-অফ (Trade-off) করতে হয়। হয়তো কখনো সময়ের বিনিময়ে স্পেস বাচানো যায়, কখনো রিলায়েবিলিটির বিনিময়ে সময় বাচানো যায়। আমরা যদি কিছুটা অ্যাকুরেসি বিসর্জন দিতে রাজি হই তাহলে সাব-লিনিয়ার স্পেসে এই সমস্যা সমাধান করা সম্ভব কাউন্ট-মিন স্কেচ ব্যবহার করে। এক্ষেত্রে জায়গা অনেক কম লাগবে কিন্তু মাঝে মধ্যে আমরা ফ্রিকুয়েন্সি ওভার-কাউন্ট (over-count) করে ফেলবো। অর্থাৎ হয়তো একটা শব্দ সার্চ করা হয়ছে ১২২৩১২ বার, কিন্তু আমরা হয়তো পাবো ১২২৩১৮ বার। এই ধরনের সিনারিওতে অনেক সময় অ্যকুরেসি একটু বেশি-কম হলেও আসলে তেমন একটা সমস্যা নাই, এটা ক্রিটিকাল কোনো সিস্টেম না যে একদম এক্সেক্ট সংখ্যাই লাগবে।
কাউন্ট-মিন স্কেচ (Sketch)
স্কেচ এমন এক ধরণের ডাটা স্ট্রাকচার যেখানে মূল ডাটার একটা সামারি রেখে দেয়া হয়। অনেক সময় সেই সামারিতে কিছুটা ভুল-ভ্রান্তি থাকে তবে সেটা টলারেবল লেভেলের। তুমি এটাকে তুলনা করতে পারো ছবির স্কেচের সাথে। অনেক সময় আর্টিস্ট মুল ছবি আকার আগে পেন্সিল দিয়ে একটা স্কেচ করে নেয়। সেখানে হয়তো অনেক ডিটেইলস থাকে না কিন্তু প্রয়োজনীয় অনেক তথ্য সেখানে থাকে।
এই প্রবলেমের জন্য আমাদের স্কেচ হলো একটা ফিক্সড সাইজের সিম্পল ২-ডি ম্যাট্রিক্স। সেটা দেখতে এরকম:
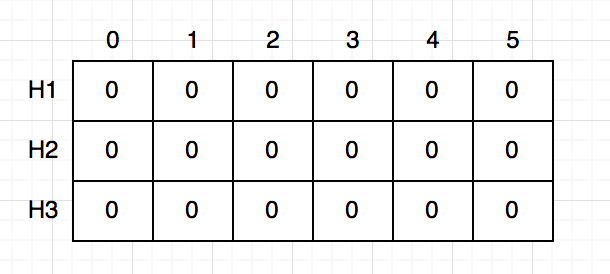
এই সমস্যা সমাধান করতে আমাদের n টা হ্যাশ ফাংশন লাগবে, স্কেচ ম্যাট্রিক্সের রো সংখ্যা হ্যাশ ফাংশনের সংখ্যা নির্দেশ করবে। এক্ষেত্রে আমরা উদাহরণ হিসাবে ধরে নিয়েছি $n = 3$। প্রতিটা হ্যাশ ফাংশনেই ফিক্সড সাইজ, প্রতিটাই 0 থেকে m-1 এর মধ্যে একটা সংখ্যা রিটার্ণ করে। আমাদের উদাহরণে $m = 6$। তো আমাদের ম্যাট্রিক্সের সাইজ হলো $3 * 6$। এই ম্যাট্রিক্সটা ব্যবহার করে কিভাবে ফ্রিকুয়েন্সি কাউন্ট করা যায় সেটা এখন আমরা দেখবো।
এখন স্ট্রিম থেকে যখন একটা শব্দ আসবে, সেই শব্দটাকে আমরা ৩ টা ফাংশন ব্যবহার করে ৩ বার হ্যাশ করবো। মনে করো হ্যাশ ফাংশন ৩টার নাম হলো H1, H2 এবং H3।
আমরা যেহেতু এখন সত্যিকারের হ্যাশ ফাংশন লিখছিনা, আমরা কল্পনায় কোন শব্দকে কোন ফাংশন দিয়ে হ্যাশ করলে কি পাওয়া যাবে সেটার একটা চার্ট তৈরি করি:
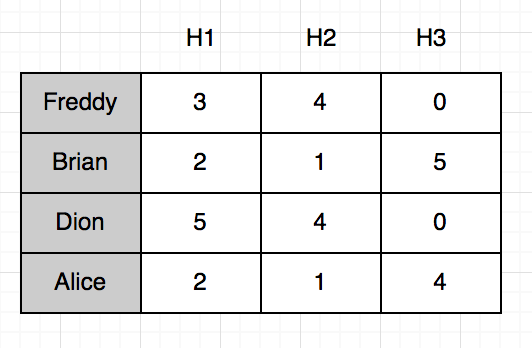
এটা একটা কাল্পনিক হ্যাশ-চার্ট। যেমন “Freddy” কে H1 দিয়ে হ্যাশ করলে $3$ পাওয়া যাবে, “Brian” কে H2 দিয়ে হ্যাশ করলে $1$ পাওয়া যাবে। যেহেতু টেবিলের সাইজ খুব ছোট, কলিশনের বেশ ভালো সম্ভাবনা আছে। যেমন “Brian” এবং “Alice” কে H1 দিয়ে হ্যাশ করলে আমরা একই সংখ্যা $2$ পাচ্ছি। পরবর্তিতে আমরা দেখবো এইটার কারণেই কিছু ওভার-কাউন্ট হবে।
আমাদের স্ট্রিমের প্রথম শব্দ হলো “Alice”। “Alice” কে হ্যাশ করলে পাওয়া যায় $H1(Alice) = 2, H2(Alice) = 1, H3(Alice) = 4$। তাহলে আমরা ফ্রিকুয়েন্সি টেবিলে (H1, 2), (H2, 1), (H3, 4) এই ঘরগুলোতে ১ যোগ করে দিবো।
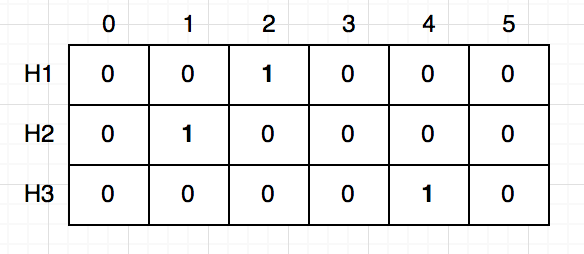 (খেয়াল রেখো, আমি বোঝানোর সুবিধা হ্যাশ-চার্টটা ব্যবহার করে এখানে টেবিল আপডেট করছি, বাস্তবে এরকম চার্ট সেভ করা সম্ভব না, তাই প্রতিবার নতুন করে হ্যাশ ক্যালকুলেট করতে হবে।)
(খেয়াল রেখো, আমি বোঝানোর সুবিধা হ্যাশ-চার্টটা ব্যবহার করে এখানে টেবিল আপডেট করছি, বাস্তবে এরকম চার্ট সেভ করা সম্ভব না, তাই প্রতিবার নতুন করে হ্যাশ ক্যালকুলেট করতে হবে।)
এরপরের শব্দটা হলো “Dion”। এবার আপডেট হবে (H1, 5), (H2, 4), (H3, 0)।
 “Brian” এর জন্য আপডেট হবে (H1, 2), (H2, 1), (H3, 5)। “Brian” পর পর দুইবার আছে, একবারেই ২ যোগ করে দেই:
“Brian” এর জন্য আপডেট হবে (H1, 2), (H2, 1), (H3, 5)। “Brian” পর পর দুইবার আছে, একবারেই ২ যোগ করে দেই:
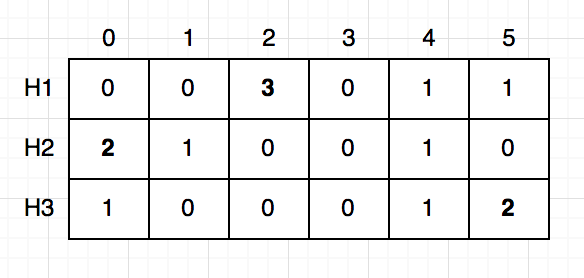 আশা করি বুঝতে পারছো কিভাবে টেবলটা আপডেট হচ্ছে। প্রতিবার একটা শব্দ পেলে আমরা ৩ বার হ্যাশ করছি এবং সেই অনুযায়ী টেবিলে ফ্রিকুয়েন্সি আপডেট করে দিচ্ছি। বাকি আছে “Freddy”, “Brian”, “Freddy”, “Dion”, এই শব্দগুলোকে একই ভাবে আপডেট করে দিলে শেষ পর্যন্ত চেহারা দাড়াবে এরকম:
আশা করি বুঝতে পারছো কিভাবে টেবলটা আপডেট হচ্ছে। প্রতিবার একটা শব্দ পেলে আমরা ৩ বার হ্যাশ করছি এবং সেই অনুযায়ী টেবিলে ফ্রিকুয়েন্সি আপডেট করে দিচ্ছি। বাকি আছে “Freddy”, “Brian”, “Freddy”, “Dion”, এই শব্দগুলোকে একই ভাবে আপডেট করে দিলে শেষ পর্যন্ত চেহারা দাড়াবে এরকম:
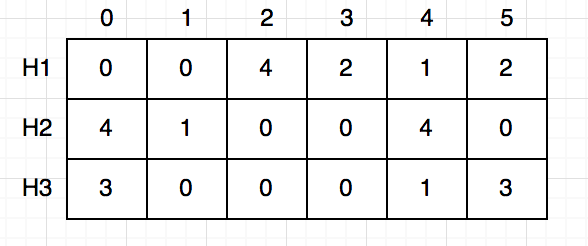 এবার এই টেবিল ব্যবহার করে আমরা যেকোনো শব্দের ফ্রিকুয়েন্স বের করতে পারি। যেমন ধরো “Dion”, আমাদেরকে আবার ৩ বার হ্যাশ করতে হবে এবং আগের মতোই আমরা ৩টা সেল পাবো (H1, 5), (H2, 4), (H3, 0)।
এবার এই টেবিল ব্যবহার করে আমরা যেকোনো শব্দের ফ্রিকুয়েন্স বের করতে পারি। যেমন ধরো “Dion”, আমাদেরকে আবার ৩ বার হ্যাশ করতে হবে এবং আগের মতোই আমরা ৩টা সেল পাবো (H1, 5), (H2, 4), (H3, 0)।
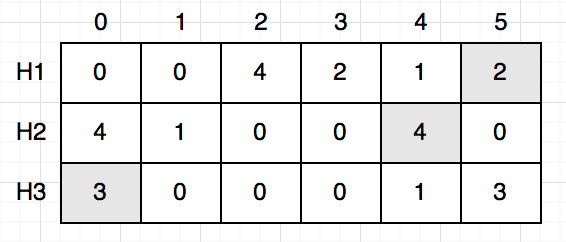 “Dion” এর জন্য এই ৩টা ঘর আমরা ইনক্রিমেন্ট করেছি। সেই হিসাবে এই ৩টা ধরেই “Dion” এর ফ্রিকুয়েন্সি থাকার কথা। কিন্তু যেহেতু হ্যাশ কলিশন হবার সম্ভাবনা আছে, একই ঘর একাধিক শব্দ দিয়ে ইনক্রিমেন্ট হতে পারে। তাই আমরা এই ৩টা ঘর থেকে মিনিমামটা বেছে নিবো, এক্ষেত্রে মিনিমাম হলো $2$। তারমানে “Dion” এর ফ্রিকুয়েন্সি $2$ যেটা আসলেই ঠিক।
“Dion” এর জন্য এই ৩টা ঘর আমরা ইনক্রিমেন্ট করেছি। সেই হিসাবে এই ৩টা ধরেই “Dion” এর ফ্রিকুয়েন্সি থাকার কথা। কিন্তু যেহেতু হ্যাশ কলিশন হবার সম্ভাবনা আছে, একই ঘর একাধিক শব্দ দিয়ে ইনক্রিমেন্ট হতে পারে। তাই আমরা এই ৩টা ঘর থেকে মিনিমামটা বেছে নিবো, এক্ষেত্রে মিনিমাম হলো $2$। তারমানে “Dion” এর ফ্রিকুয়েন্সি $2$ যেটা আসলেই ঠিক।
সমস্যা হবে তখনই যখন কলিশন অনেক বেড়ে যাবে। যদি নতুন একটা শব্দ Mary আসে এবং শব্দটি (H1, 5), (H2, 3), (H3, 1) সেলগুলোকে আপডেট করে দেয় তাহলে টেবিলটা দাড়াবে এরকম:
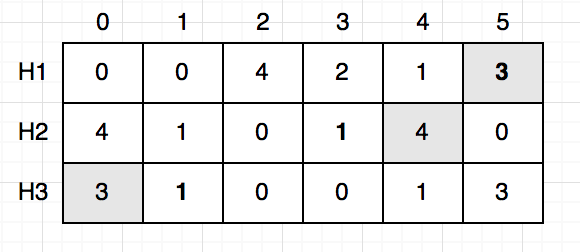 আমি ইচ্ছা করেই “Dion” এর ঘরগুলোকে এখনো হাইলাইট করে রেখেছি। এবার কিন্তু আমরা “Dion” এর ফ্রিকুয়েন্সি পাবো $3$ যেটা ভুল।
আমি ইচ্ছা করেই “Dion” এর ঘরগুলোকে এখনো হাইলাইট করে রেখেছি। এবার কিন্তু আমরা “Dion” এর ফ্রিকুয়েন্সি পাবো $3$ যেটা ভুল।
আগেই বলেছি মিন-কাউন্ট স্কেচ মাঝমধ্যে ওভার কাউন্ট করবে হ্যাশ কলিশনের জন্য। যেসব সিনারিওতে অল্প কিছু এরোর টলারেট করা সম্ভব সেসব ক্ষেত্রে এটা খুব ভালো পারফরমেন্স দিবে। তোমার ডাটাসেট যতই বড় হোক, টাইম এবং স্পেস কমপ্লেক্সিটি Constant থাকছে। অ্যাকুরেসি এক্ষেত্রে নির্ভর করবে তুমি কয়টা হ্যাশ ফাংশন ব্যবহার করছো (n) এবং প্রতিটা হ্যাশ ফাংশনের বাকেট সংখ্যার (m) উপর। এগুলো যত বড় হবে তত কলিশন কমে যাবে। তবে মনে রাখতে হবে, স্ট্রিং হ্যাশ করা বেশ এক্সপেনসিভ একটা অপারেশন, তাই হ্যাশ ফাংশন খুব বেশি না বাড়ানোই ভালো এবং এমন হ্যাশ ফাংশন ব্যবহার করা উচিত যেটা খুব দ্রুত কাজ করে। সেক্ষেত্রে ক্রিপ্টোগ্রাফিক হ্যাশ ফাংশন যেমন SHA-256 খুব একটা ভালো কাজ করবে না, হ্যাশ ফাংশনের স্পিডের উপর একটা অ্যানালাইসিস এখানে দেখতে পারো।
একটা ব্যাপার লক্ষনীয়, কাউন্ট-মিন স্কেচ শুধু মাত্র ওভার-কাউন্ট করতে পারে, আন্ডার-কাউন্ট না। তো এটা একধরণের Bias যেটাও দূর করার কিছু টেকনিক আছে যেটাকে বলা হয় Count-mean-min-sketch। এক্ষেত্রে হ্যাশ করার পর মাঝের সংখ্যা (mean) বের করে সেটাকে সবগুলো ঘর থেকে বিয়োগ দিয়ে দেয়া হয়।
দেখতেই পাচ্ছো ডাটা স্ট্রাকচারের নলেজ দিয়ে কিভাবে আমরা সহজেই একটা সিস্টেম বিশাল পরিমাণ ডাটার জন্য প্রস্তুত করে ফেললাম! হ্যাপি কোডিং!

ফেসবুকে মন্তব্য
Powered by Facebook Comments