আজকে কথা বলবো ডেটাবেজ বানাতে ব্যবহার করা হয় এমন একটি ডেটা স্ট্রাকচার নিয়ে। সাধারণত ডেটাবেসের সাথে আমাদের পরিচয় হয় Sql ধরণের ট্রানজেকশনাল ডেটাবেজ দিয়ে, যেমন MySQL, PostGreSQL। এসব ডেটাবেসে বি+ ট্রি (B+ Tree) ব্যবহার করে ডেটা সংরক্ষণ করা হয়। এই লেখায় আমি আলোচনা করবো ডেটাবেজ তৈরি করতে জনপ্রিয় আরেকটি ডেটা স্ট্রাকচার নিয়ে যার নাম লগ-স্ট্রাকচার্ড-ট্রি বা সংক্ষেপে LSM Tree।
আগেই বলে নেই, এটা প্রোগ্রামিং কনটেস্টে ব্যবহার করার মত কোন ডেটা স্ট্রাকচার না। তবে সফটওয়্যার ইঞ্জিনিয়ারারদের কেন ডেটা স্ট্রাকচার, অ্যালগরিদম এবং হার্ডওয়্যার নিয়ে জানা দরকার তার একটা উদাহরণ এই LSM Tree।
ব্যাকএন্ড ইঞ্জিনিয়ারিং নিয়ে যারা কাজ করছে তাদের প্রায়ই NoSQL ডেটাবেজ যেমন হাইভ, বিগটেবল, রকস-ডিবি এসব নিয়ে কাজ করতে হয়। এসব ডেটাবেজ বেশিভাগই LSM Tree ব্যবহার করে তৈরি। LSM Tree সম্পর্কে জানা থাকলে ডেটাবেজের পারফরমেন্স অপটিমাইজ করা অথবা কোন ডেটাবেজ ব্যবহার করলে ভালো ফলাফল পাওয়া যাবে সেই বিষয়ে সিদ্ধান্ত নিতে সুবিধা হবে।
আমি আশা করবো যারা এই লেখা পড়ছে তাদের ডেটাবেজ নিয়ে কাজ করার অল্প হলেও অভিজ্ঞতা আছে, ডেটাবেজ ইনডেক্স বা SQL/NoSql এর পার্থক্য সম্পর্কে জানে।
মোটা দাগে যেকোন ডেটাবেজ দুই ধরণের অপারেশন করা হয়, ডেটা পড়া (Read) অথবা ডেটা লেখা (Write)। কোন কোন ডেটাবেজ থেকে ডেটা খুব দ্রুত পড়া যায় কিন্তু লেখার গতি কিছুটা কম, আবার কোন কোন ডেটাবেজে দ্রুত ডেটা প্রবেশ করানো গেলেও ডেটা পড়ার পারফরমেন্স কিছুটা খারাপ। কোন ধরণের ডেটাবেজ তুমি ব্যবহার করতে সেটা তোমার সিস্টেমের রিকোয়ারমেন্টসের উপর নির্ভর করে। তুমি যদি এস.এস.সি পরীক্ষার ফলাফল প্রকাশের জন্য অ্যাপ বানাতে চাও তাহলে অবশ্যই ডাটা রিড করার দিকে বেশি গুরুত্ব দিবে, কিন্তু তুমি যদি ডেটাবেসে একটা ই-কমার্স সাইটে ইউজার কোথায় কখন ক্লিক করছে সেটা সেভ করতে চাও পরবর্তিতে অ্যানালাইসিস করার জন্য তাহলে Write এর উপর গুরুত্ব দিতে হবে।
LSM Tree ট্রি মূলত গুরুত্ব দেয় Write অপারেশনের উপর, আর বি+ ট্রি বেসড ডেটাবেজ বেশী ভালো কাজ করে যখন রিড অপারেশন বেশি থাকে। এছাড়াও আরো পার্থক্য আছে, সেসব নিয়ে পরে জানবো।
সিকুয়েন্সিয়াল রিড-রাইট
LSM Tree নিয়ে জানতে হলে আমাদের একটু লো-লেভেলে যেতে হবে। যেকোন স্টোরেজ ডিভাইসে (যেমন হার্ডডিস্ক) ডেটা সেভ করার জন্য ছোট ছোট ব্লকে ভাগ করা হয়। প্রতিটা ব্লকে কিছু বাইট সেভ করা হয়। এখন যদি তোমার ডেটা পাশাপাশি ব্লকে সেভ করা হয় তাহলে কিছু সুবিধা আছে।
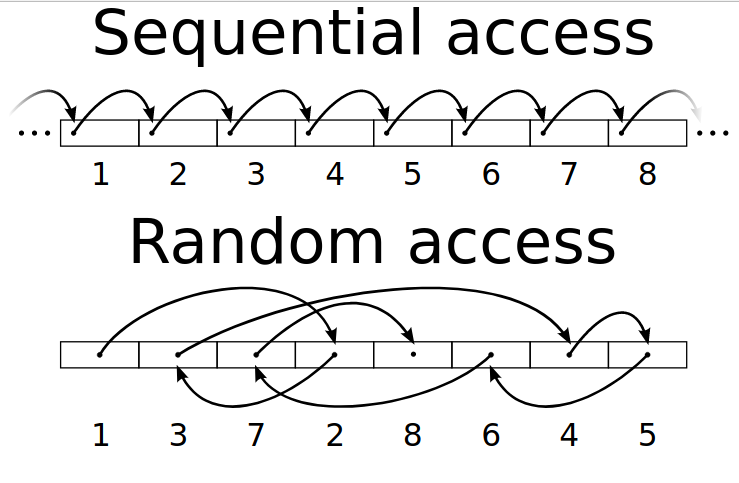
সিকুয়েন্সিয়াল এক্সেস মানে হলো পাশাপাশি রাখা ডাটাগুলো এক এক করে এক্সেস করা। আর Random এক্সেস এর ক্ষেত্রে আমাদেরকে এক ব্লক থেকে অন্য দূরের ব্লকে লাফ দিয়ে যেতে হয়।
স্টোরেজ ডিভাইস হিসাবে কিছুদিন আগেও সবজায়গায় হার্ডডিস্ক (HDD – Hard disk drive) ব্যবহার করা হতো। হার্ডডিস্কে একটা গোল চাকতি ঘুরতে থাকে আর একটা পিন সামনে-পিছে সরিয়ে নির্দিষ্ট ব্লক থেকে ডেটা পড়া হয়। বুঝতেই পারছো, হার্ডডিস্কে ডাটা রেন্ডম এক্সেস করতে স্বাভাবিক ভাবেই বেশি সময় লাগবে কারণ পিনের লোকেশন বারবার পরিবর্তন করতে হবে। যারা Windows 98 এর সময় কম্পিউটার ব্যবহার করেছো, তাদের নিশ্চয়ই মনে আছে ডিস্ক ডিফ্র্যাগমেন্ট সফটওয়্যারটার কথা। ওটার কাজই ছিলো এলোমেলো ভাবে রাখা ডেটাকে পাশাপাশি সাজানো।
বর্তমানে ডেটা সেন্টার গুলোতে সলিড স্টেট ড্রাইভ (SSD) ব্যবহার করা হয়, বেশিভাগ নতুন মডেলের ল্যাপটপ গুলোতেও SSD জনপ্রিয়। SSD তে কোন চাকতি থাকে না, বরং সেমিকন্ডাক্টরের মধ্যে ডেটা রেখে দেয়া হয়। SSD এর রিড-রাইট পারফরমেন্স সনাতন হার্ডডিস্কের তুলনায় অনেক ভালো। এক্ষেত্রে রেন্ডম এক্সেস আর সিকুয়েন্সিল এক্সেসের পার্থক্য অনেকটা কমে আসলেও সিকুয়েন্সিয়াল এক্সেস কিছুটা ভালো পারফরমেন্স দেয়। আমরা যখন কয়েক টেরাবাইট ডেটা রাইট করবো তখন এই পার্থক্যই খুবই গুরুত্বপূর্ণ।
ডেটা স্ট্রাকচার নিয়ে কথা বলতে গিয়ে এসব টেনে আনার কারণ হলো, LSM Tree সবসময় সিকুয়েন্সিয়াল ভাবে ডেটা সেভ করে, এতে করে রাইট পারফরমেন্স অনেকগুণে বেড়ে যায়। বি+ ট্রি এর স্ট্রাকচারের কারণে সবসময় সিকুয়েন্সিয়াল রাইট করা সম্ভব হয় না।
লগ স্ট্রাকচার
লগ সম্ভবত পৃথিবীর সবথেকে সহজ ডেটা স্ট্রাকচার। সাধারণত লগিং বলতে বোঝায় কখন কি ঘটনা ঘটছে সেটা একের পর এক লিখে রাখা। টেক্সট ফাইল বা বাইনারি ফাইল ব্যবহার করেই সেই কাজটা করা যায়। তুমি যখন কোন একটা ওয়েবসাইটে ব্রাউজ করছো তখন তুমি কোথায় কখন ক্লিক করছো, কখন কোন পেজ দেখছো সেগুলো একটা লগ ফাইলে লেখা হতে থাকে। পরবর্তিতে এই লগ ফাইল মেশিন লার্নিং কোন অ্যালগরিদম দিয়ে অ্যানালাইসিস করে তোমার পছন্দ-অপছন্দ বের করে ফেলা যায়, ইকমার্স বা সোস্যাল নেটওয়ার্ক সাইটগুলো এসব প্রতিনিয়তই করতে থাকে।
ডেটাবেজে লগ দরকার হয় ডেটা রিকভার করার জন্য। তুমি যখন ডেটাবেজে বিভিন্ড আপডেট কমান্ড দাও তখন একটা লগ ফাইলে সেই কমান্ডটা লেখা হতে থাকে, এরপরে ডেটাবেজে সেই আপডেটটা করা হয়। এতে করে আপডেট করার আগে ডেটাবেজ ক্র্যাশ করলেও লগ থেকে সেই ডেটাবেজ রিকভার করা যায়। এধরণের লগকে Write Ahead Log (WAL) বলে। এই লেখাটি পড়ার পরে তুমি WAL নিয়ে গুগলে ঘাটাঘাটি করে বিস্তারিত জেনে নিও।
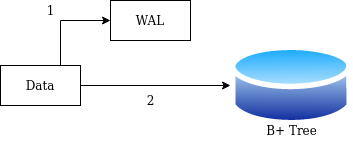
লগ ফাইলের গুরুত্বপূর্ণ বৈশিষ্ট্য হলো, এখানে শুধু একের পর এক ডেটা লিখে যাওয়া হয়, এটা একটা Append Only ডেটা স্ট্রাকচার। সাধারণত এই ফাইলি লিখে ফেলা কোন ডেটার কোন পরির্তন করা হয় না। সেই কারণে লগ ফাইল সেভ করার সময় আমরা সিকুয়েন্সিয়াল রাইটের সুবিধাটা নিতে পারি। কিন্তু ডেটা যখন বি+ ট্রিতে লেখা হচ্ছে, তখন রেন্ডম এক্সেস করতেই হচ্ছে।
বি+ ট্রি এর জায়গায় LSM Tree ব্যবহার করে আমরা মূল ডেটাবেজেও সিকুয়েন্সিয়াল রাইট করতে পারি। আমরা এখন সেটাই দেখবো।
সর্টেড স্ট্রিং টেবিল (SSTable)
ধরা যাক আমরা ডেটাবেজের ডেটাগুলো বি+ ট্রি তে না রাখে লগ-ফাইলে রাখছি। একটা ফাইলে রাখলে বেশি বড় হয়ে যাবে দেখে ছোট ছোট অনেকগুলো ফাইলে ভাগ করে রাখতে হবে। আমাদের ডেটা হলো জাস্ট কিছু কি-ভ্যালু (key-value) পেয়ার। তো লগফাইলগুলো দেখতে হতে পারে এরকম:
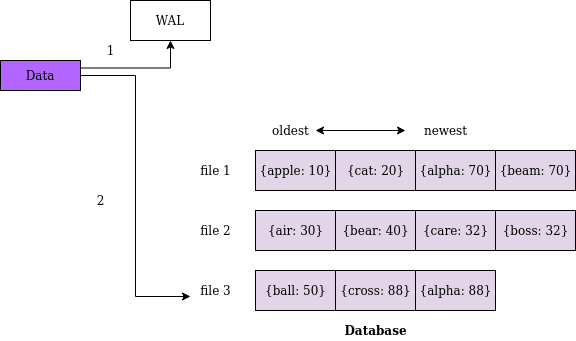
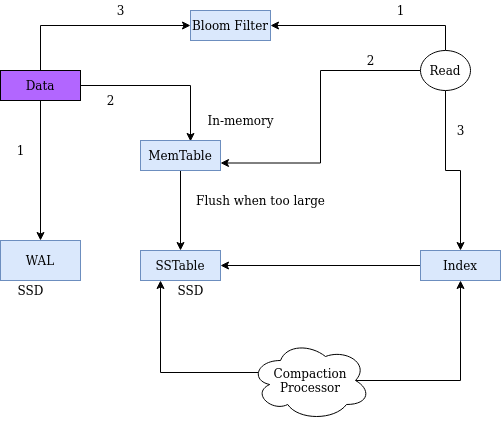
এখানে দুই জায়গায় লগ ব্যবহার করছি। প্রথমেই আমাদের ডেটা WAL এ লিখে রাখছি যাতে কোন সমস্যা হলে ডেটা রিকভার করা যায়। তারপর মূল ডেটাবেজেও লগ আকারে সেভ করে রাখছি। প্রতিবার নতুন ডেটা আসলে আমরা ডেটাবেজে সর্বশেষ ফাইলে লেখার চেষ্টা করবো। ফাইল বেশি বড় হয়ে গেলে নতুন ফাইল তৈরি করবো।
ডেটা একবার লেখা হয়ে গেলে সেটা আর পরিবর্তন করা যাবে না, যদি ডেটা আপডেট করা দরকার হয় তাহলে নতুন একটা এন্ট্রি করতে হবে। ডেটা ডিলিট করতে হলেও নতুন key ইনসার্ট করে সেখানে বিশেষ কোন ফ্ল্যাগ দিয়ে মার্ক করে দিতে হবে, এটাকে বলে হয় Tombstone ডেটা। (সেজন্য ডেটাবেসে অনেক ডুপ্লিকেট ডেটা তৈরি হবে, সেই সমস্যার সমাধান একটু পরে বলছি)
এখন সমস্যা হলো তুমি এখন থেকে ডাটা পড়বে কিভাবে? একটাই উপায়, সবগুলো ফাইলে লিনিয়ার সার্চ করা। যেহেতু ডেটা নতুন থেকে পুরানো এই ক্রমে সাজানো আছে, তোমাকে খোজা শুরু করতে হবে শেষ ফাইলের শেষ ডেটা থেকে। বুঝতেই পারছো এভাবে সার্চ করা ভালো কোন বুদ্ধি না।
একটা সমাধান হলো ইনডেক্সিং করা। তারমানে তোমাকে অন্য আরেকটা হ্যাশম্যাপে কোন ডেটা কোথায় আছে সেটার পজিশন সেভ করে রাখতে হবে। সমস্যা হলো প্রতিটা ডেটা এভাবে ইনডেক্স করতে হলে হ্যাশম্যাপের সাইজও বিশাল হয়ে যাবে, সেটা তুমি মেমরিতে সেভ করতে পারবে না।
আমরা যদি প্রতিটা ফাইল সর্ট করে রাখতে পারি তাহলে কিন্তু কাজ অনেকটা সহজ হয়ে যায়।
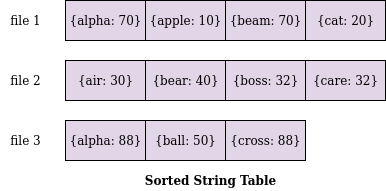
এবার আমরা ফাইলগুলো সর্ট করে রেখেছি, কিভাবে সর্টিং টা করা হলো সেটা একটু পরেই বলছি। এই পুরো স্ট্রাকচার টাকে বলা হয় সর্টেড স্ট্রিং টেবিল। প্রতিটা ফাইলকে অনেক সময় সেগমেন্টও বলা হয়।
এখন তুমি হয়তো ভাবতে পারো প্রতিটা ফাইলে বাইনারি সার্চ করবে। ডেটা যখন মেমরিতে থাকে তখন বাইনারি সার্চ করা খুব সহজ কিন্তু এ ধরণের ফাইলে সেটা খুব কঠিন, কারণ তুমি জানো না যে ফাইলের কোন key কোন লোকেশনে রাখা হয়েছে।
সাধারণত এসব ঝামেলায় না গিয়ে প্রতিটা ফাইলের জন্য বিশেষ এক ধরণের ইনডেক্স ব্যবহার করা হয়।
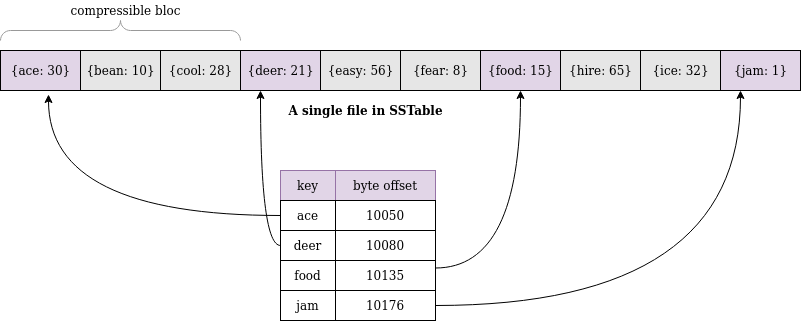
উপরের ছবিতে টেবিলের একটা সর্টেড ফাইল এবং সেটার ইনডেক্স দেখানো হয়েছে। ইনডেক্সে আমরা অল্প কিছু ডেটার লোকেশন সেভ করে রেখেছি। এধরণের ইনডেক্সকে বলা হয় Sparse Index।
এবার কোন একটা সেগমেন্টে বা ফাইলে ডেটা খোজার সময় ইনডেক্স দেখে আমরা বলতে দিতে পারি ফাইলের কোন লোকেশনে ডেটা আছে। যেমন bean খুজতে হলে আমরা ইনডেক্স দেখে বুঝতে পারবো যে ace এবং cool এর মাঝামাঝি কোথাও খুজতে হবে। এরপর সেই অংশটুকুতে লিনিয়ার সার্চ করতে হবে।
এখানে একটা ট্রেডঅফের ব্যাপার আছে, ইনডেক্স যত বেশি স্পার্স হবে, লিনিয়ার সার্চ করতে তত বেশি সময় লাগবে, আবার ইনডেক্সে যত বেশি এন্ট্রি থাকবে, মেমরি তত বেশি খরচ হবে, ডিজাইন করার সময় তোমাকে এসব কনফিগারেশনের ব্যাপারে সতর্ক থাকতে হবে। সাধারণত কয়েক কিলোবাইট ডেটার জন্য ইনডেক্সে একটি করে এন্ট্রি করাই যথেষ্ট। ইনডেক্সের একটা কপি ডিস্কেও সেভ করে রাখা হয়, যাতে সার্ভার ক্র্যাশ করলে আবার সহজে ইনডেক্সটা মেমরিতে লোড করা যায়।
যেহেতু দুই ইনডেক্সের মাঝামাঝি অংশে লিনিয়ার সার্চ করাই লাগছে, আমরা চাইলে সেই অংশটা কমপ্রেস করে রাখতে পারি কিছু স্পেস বাচানোর জন্য।
একটা সমস্যা থেকেই গেল, এখনো আমাদের প্রতিটা ফাইলে গিয়ে গিয়ে খুজতে হচ্ছে, ফাইলের সংখ্যা যদি অনেক বেশি হয়ে যায় তাহলে সেটা সমস্যা তৈরি করবে। সেটার একটা সমাধান হলো পুরানো ফাইলগুলোকে মার্জ করে ফেলা, এটা নিয়ে বিস্তারিত একটু পরেই দেখবো।
মনে করো দেখ যে, ফাইলগুলোতে কিন্তু একটার পর একটা ডেটা রাইট করা হচ্ছে। লগ ফাইলে একবার ডেটা লেখা হয়ে গেলে সেটাকে আর সর্ট করার উপায় নেই। তাহলে আমাদেরকে একটা বুদ্ধি বের করতে হবে যাতে ডাটা রাইট করার সময়ই সর্টেড থাকে।
মেমটেবিল (MemTable)
এতক্ষণ আমরা ডেটা পাওয়ার পর লগ ফাইলে (WAL) এবং SSTable এ লিখে রাখছিলাম। কিন্তু সমস্যা হচ্ছিলো সর্টিং নিয়ে। আমরা যদি চাই যেকোন ডাটা ঢুকানোর সময় সর্ট করে ঢুকাবো তাহলে কোন ডেটা স্ট্রাকচারের কথা মাথায় আসে? অবশ্যই বাইনারি সার্চ ট্রি। কিন্তু ডিস্কেতো বাইনারি সার্চ ট্রি সরাসরি সেভ করাটা একটু ঝামেলা, বিশেষ করে যদি সিকুয়েন্সিয়াল রাইট এর সুবিধাটা নিতে চাই। সেক্ষেত্রে আমরা মেশিনের মেমরিতে একটা বাইনারি ট্রি সেভ করে রাখতে পারি, এটার নামই মেমটেবিল (MemTable) বা ইন-মেমরি টেবিল।
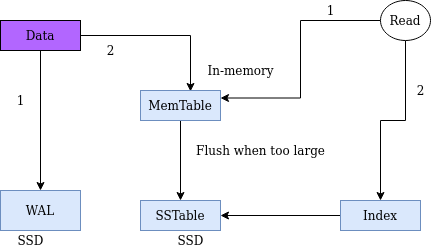
এবার আমাদের ফ্লো তে সামান্য একটু পরিবর্তন এসেছে। আমরা ডেটা SSTable এ লেখার আগে একটা ইন-মেমরি বাইনারি সার্চ ট্রিতে সর্টেড আকারে সেভ করে রাখবো। যখনই দেখবো মেমটেবিলের সাইজ বেশি বড় হয়ে গেছে তখন সেটাকে খালি করে SSTable এ ডেটাগুলোকে সরিয়ে ফেলবো। এটাকে ডেটা flush করা বলে।
এবার আমাদের ডেটা পড়ার সময় খালি SSTable এ খুজলে হবে না কারণ নতুন ডেটা হয়তো তখনো ফ্লাশ করা হয়নি। তাই প্রথমে মেমটেবলে খুজে তারপর SSTable এ খুজতে হবে।
কম্প্যাকশন (Compaction)
আমাদের এখনো একটা সমস্যা থেকে গেছে। SSTable হলো ছোট ছোট অনেকগুলো সর্টেড ফাইলের সমন্বয়, সেটা আমরা আগেই জেনেছি। কখনো ডেটা আপডেট বা ডিলিট করা হলে আমরা আগের ডেটার কোন পরিবর্তন না করে নতুন ডেটা ইনসার্ট করেছি। সেজন্য অনেক ডুপ্লিকেট ডেটা তৈরি হবে যেটা আমরা চাইনা। আবার আমরা ডেটা রিড করার সময় দেখেছি আমাদের সবগুলো ফাইলে গিয়ে গিয়ে খুজতে হয়, ফাইলের সংখ্যা বেশি হয়ে গেলে খুজতে সময় বেশি লাগবে। সবথেকে ভালো হত যদি অল্প কিছু ফাইলে ডেটাগুলো রেখে দেয়া যত।
Compact কথাটার অর্থ আটোসাটো, আমরা যখন লাগেজে জিনিসপত্র ঢুকাই তখন আটোসাটো করে না ঢুকালো অনেক জায়গা নষ্ট হয়, এখানেও ব্যাপারটা এরকম। একটা প্রসেস আমাদের ব্যাকগ্রাউন্ডে চলতে থাকবে যার কাজ ডাটাকে কম্প্যাক্ট করা। সে যখনই দেখবে অনেকগুলো ছোট ছোট ফাইল তৈরি হয়ে গেছে, সে ওই ফাইলগুলোকে নিয়ে মার্জ করে একটি বড় ফাইল বানিয়ে ফেলবে।
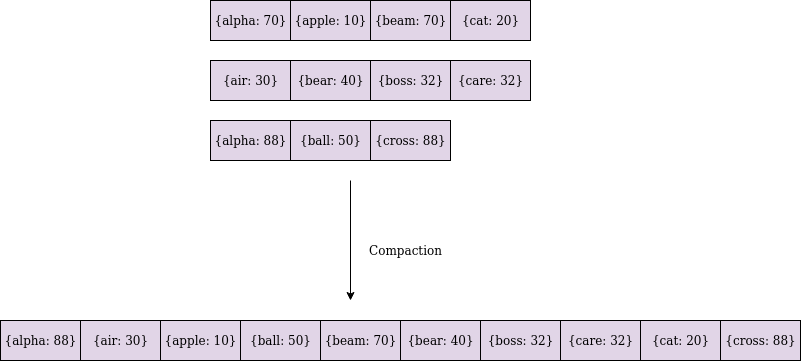
প্রতিটা সেগমেন্ট সর্টেড থাকায় খুব সহজেই এদেরকে মার্জ করা সম্ভব। তোমরা হয়তো অনেকেই Merging k sorted linked list সমস্যাটা সমাধান করেছো, কম্প্যাকশন প্রসেস ঠিক এই কাজটাই করে।
কম্প্যাকশন প্রসেসের আরেকটা কাজ হলো ইনডেক্স আপডেট করা, সেগমেন্ট মার্জ করার সময় ইনডেক্সগুলোও আপডেট করে দেয় এবং পুরানো সেগমেন্টগুলো মুছে ফেলা হয়।
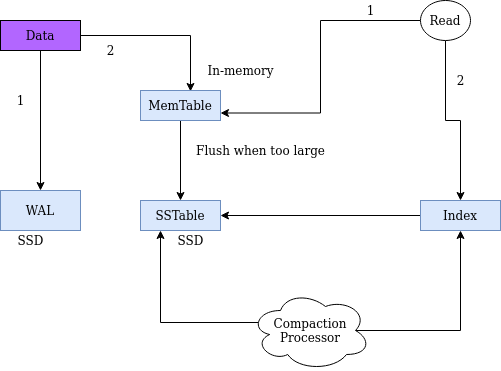
আমরা ফ্লো চার্টে কম্প্যাকশন প্রসেসর যোগ করে দিলাম। কম্প্যাকশন প্রসেসটা আমি খুব সিম্পল ভাবে বললেই বাস্তবে কিছুটা জটিল কারণ সেসময় ডেটা রাইট করা বন্ধ রাখতে হয়। মাল্টি থ্রেডিং ব্যবহার করে কম্প্যাকশনের গতি বাড়ানো যায়। সেসব বর্ণনায় আমি এখন যাবো না।
ব্লুম ফিল্টার
আগেই বলেছি LSM Tree তে ডেটা খুজে বের করতে বি+ ট্রি এর থেকে একটু বেশি সময় লাগে। তাই আমরা খোজাখুজির কাজ যতটা সম্ভব কম করতে চাই। ব্লুম ফিল্টার ব্যবহার করে আমরা খুব দ্রুত বলে দিতে পারি কোন একটা ডেটা আছে নাকি নেই। সমস্যা হলো ব্লুম ফিল্টার প্রোবাবিলিস্টিক ডেটা স্ট্রাকচার, যদি ডেটা না থাকে সে নিশ্চিত করে বলে দিতে পারে ‘নাই’, কিন্তু সে যদি বলে ডেটা আছে তাহলে কিছুটা সম্ভাবনা থেকে যায় যে ডেটা নাই। এটা কিভাবে কাজ করে সেটা নিয়ে আমার একটা লেখা আছে, তুমি পরে দেখতে পারো। আপাতত এটুকু জানলেই চলবে যে ব্লুম ফিল্টার মেমরিতে খুব কম জায়গা নেয়, ১ মেগাবাইটের কম সাইজের ব্লুম ফিল্টারে ১ মিলিয়ন স্ট্রিং ঢুকিয়ে রাখা যায়। O(1) কমপ্লেক্সিটিতে ব্লুম ফিল্টার থেকে ডেটা পড়া যায়।
আমরা ডেটা মেমটেবিলে লেখার সাথে সাথে ব্লুম ফিল্টারেও ঢুকিয়ে রাখতে পারি। রিড রিকুয়েস্ট পেলে সবার আগে ব্লুম ফিল্টারকে জিজ্ঞেস করবো ডেটা আছে নাকি নাই। সে যদি বলে নাই, তাহলে আর খোজার দরকার নেই, সে যদি বলে আছে তখন আমরা নিশ্চিত হবার জন্য মেমটেবিল আর ডেটাবেসে খুজে দেখবো।
শেষ কথা
এইবার মোটামুটি ভালো একটা ডেটাবেস ডিজাইন করে ফেলেছি। গুগলের তৈরি করা একটা জনপ্রিয় ডেটাবেজ আছে লেভেল-ডিবি যেটা LSM-Tree দিয়ে তৈরি করা। পরে ফেসবুক সেটাকে ফর্ক করে আরো উন্নত আরেকটা ডেটাবেস তৈরি করেছে যার নাম রকস-ডিবি। এছাড়াও আরো অনেক no-sql ডেটাবেজ কাছাকাছি ধরণের স্ট্রাকচার ব্যবহার করে।
একটা ব্যাপার লক্ষ্য করো, উপরের ডিজাইনে আমরা ডেটাবেজে একবার ডেটা রাইট করলেও আসলে সেই ডেটা যাচ্ছে অন্তত ৪ জায়গায় (ইনডেক্স, WAL, SSTable, ব্লুম ফিল্টার), অর্থাৎ Write Amplification হচ্ছে। এটা অবশ্য শুধু LSM-Tree এর সমস্যা না, বি+ ট্রি দিয়ে বানানো ডেটাবেজে এই জিনিস আরো অনেক বেশি হয়।
LSM-tree ডেটা দ্রুত রাইট করার জন্য ভালো, তবে কম্প্যাকশন প্রসেসটা ঠিকমত কনফিগার করা না হলে হিতে বিপরীত হতে পারে কারণ ডেটা মার্জ করার সময় কিছুক্ষণের জন্য রাইট বন্ধ থাকে।
এরপরে তোমার কাজ হবে বি+ ট্রি নিয়েও পড়ালেখা করে দুই ধরণের ডেটাবেসের তুলনা করা, তাহলে তোমার জানাটা আরো শক্ত হবে। যেমন বি+ ট্রিতে বিভিন্ন রকমের জয়েন অপারেশন করা যায় যেটা LSM-tree তে যায় না।
রেফারেন্স
এই লেখার রেফারেন্স হিসাবে বেশ কিছু ব্লগ এবং একটি বই ব্যবহার করেছি। সেগুলোর লিংক নিচে দিয়ে দিলাম:
https://medium.com/swlh/log-structured-merge-trees-9c8e2bea89e8
https://medium.com/databasss/on-disk-io-part-3-lsm-trees-8b2da218496f
https://www.amazon.sg/gp/product/1449373321/ref=ppx_yo_dt_b_asin_title_o00_s00?ie=UTF8&psc=1
হ্যাপি কোডিং

ফেসবুকে মন্তব্য
Powered by Facebook Comments