আজকাল আমাদেরকে অনেক সময়ই বড় বড় ফাইল নিয়ে প্রসেসিং করে বিভিন্ন রকম ডেটা কালেকশন করতে হয়। যেমন পপুলার কোন ওয়েবসাইটে শুধুমাত্র প্রতিদিনের সার্ভার লগ গুলোই কয়েকশ গিগাবাইট হয়ে যেতে পারে। গিগাবাইট বা টেরাবাইট রেঞ্জের ফাইল নিয়ে কাজ করতে গেলে দেখা যায় একটা মাত্র মেশিনের স্টোরেজ ক্যাপাসিটি বা কম্পিউটিং পাওয়ার যথেষ্ট হয় না। একটা মেশিনে হয় যথেষ্ট হার্ডডিস্ক স্পেস থাকে না, আবার হার্ডডিস্কে স্পেস থাকলেও দেখা যায় র্যামে যথেষ্ট জায়গা থাকেনা, সম্পূর্ণ ফাইল র্যামে লোড করে প্রসেসিং সম্ভব হয় না। “ডিস্ট্রিবিউটেড ফাইল সিস্টেম” এর কাজ হলো একটা ফাইলকে ছোট ছোট অনেকগুলো ভাগ করে বিভিন্ন মেশিনে স্টোর করে রাখা।
আমরা আজকে ফাইল সিস্টেম নিয়ে জানবো এবং একটা “ডিস্ট্রিবিউটেড ফাইল সিস্টেম” এর আর্কিটেকচার দেখবো। এই লেখাটা পড়ার পর ডিস্ট্রিবিউটেড সিস্টেমের বিভিন্ন টপিক, যেমন ডেটা রেপ্লিকেশন, লিডার-ফলোয়ার আর্কিটেকচার ইত্যাদি নিয়ে জানতে পারবে।
ফাইল সিস্টেম
তুমি যদি কখনো নিজের কম্পিউটারে লিনাক্স/উইন্ডোজ সেটাপ করো বা হার্ডডিস্ক পার্টিশন/ফরমেট করো তাহলে হয়তো তুমি FAT32, NTFS, EXT ইত্যাদি শব্দের সাথে পরিচিত। এগুলো হলো বিভিন্ন রকমের ফাইল সিস্টেম। ফাইল সিস্টেমের কাজ হলো তোমার কম্পিউটারের ফাইলগুলো কিভাবে হার্ডডিস্কে সাজানো থাকবে, কোন মেমরি ব্লকে কোন ডেটা থাকবে, কিভাবে পুরানো ডেটা এক্সেস করা হবে এসব ব্যাপার-স্যাপার নিয়ন্ত্রণ করা।
তুমি ব্যাপারটাকে তুলনা করতে পারো তোমার বাড়িতে নিজের ফাইলপত্র, ডকুমেন্টস সাজানোর সাথে। কাগজপত্র যাতে সহজে খুজে পাওয়া যায় সেজন্য হয়তো তুমি বিভিন্ন ড্রয়ারে বিভিন্ন রকমের কাগজপত্র গুছিয়ে রেখেছো, এটাকেও তুমি একধরণের ফাইল সিস্টেম বলতে পারে।
তুমি যখন একটা হার্ডডিস্কের সব ডেটা মুছে ফেলতে ফরমেট করো তখন সেটার ফাইল সিস্টেমও কিন্তু মুছে যায়। তাই ফরমেট করার সময় আমাদের অপশন দেয়া হয় একটা ফাইল সিস্টেম বেছে নিতে। ফরমেট করার পর হার্ডডিস্কে জাস্ট একটা নতুন ফাইল সিস্টেম ইনিশিয়ালাইজ করে দেয়া হয় যাতে তুমি নতুন ডেটা সেখানে সাজিয়ে রাখতে পারো।
FAT32, NTFS এগুলো হলো ডিস্ক ফাইল সিস্টেম, এদের কাজ একটা হার্ডডিস্ক নিয়ে কাজ করা। তোমার কম্পিউটারে একাধিক হার্ডডিস্ক থাকলে একেকটা হার্ডডিস্ক একেকটা ফাইল সিস্টেম নিয়ন্ত্রণ করে, একজন সব নিয়ন্ত্রণ করে না। একটা ফাইল যদি একাধিক কম্পিউটারে ভাগ করে রাখতে চাও তাহলে তোমার দরকার হবে ডিস্ট্রিবিউটেড ফাইল সিস্টেম।
ডিস্ট্রিবিউটেড ফাইল সিস্টেম
আমরা এখন একটা ডিস্ট্রিবিউটেড ফাইল সিস্টেমের আর্কিটেকচার ডিজাইন দেখবো।
তুমি যদি এক্সপেরিয়েন্সড ইঞ্জিনিয়ার হও তাহলে তুমি বাকিটা পড়ার আগে একটু নিজে নিজে চিন্তা করতে পারো কিভাবে একটা ডিস্ট্রিবিউটেড ফাইল সিস্টেম ডিজাইন করা যেতে পারে। যেসব বিষয় মাথায় রাখতে হবে সেটা হলো কিভাবে একটা ফাইলকে টুকরো করা হবে, কে সিদ্ধান্ত নিবে ক্লাস্টারের কোন মেশিনে কোন ডেটা যাবে, একটা মেশিন নষ্ট হয়ে গেলে ডেটার কি হবে ইত্যাদি।
ডিস্ট্রিবিউটেড ফাইল সিস্টেমের মেশিন গুলো একই লোকাল নেটওয়ার্কের ভিতরে থাকে এবং নিজেদের মধ্যে যোগাযোগ করতে পারে। তবে সাধারণত এই ধরণের ফাইল সিস্টেমে আপলোড করা ফাইল এডিট করা যায় না, দৈনন্দিন কাজের ওয়ার্ড/এক্সেল ফাইল স্টোর করা এই ধরণের ফাইল সিস্টেমের উদ্দেশ্য না, আমাদের উদ্দেশ্য বড় বড় ফাইল স্টোর করে রাখা যেগুলো পরবর্তিতে অফলাইনে অ্যানালাইসিস করা হবে।
প্রথমেই আমাদের কিছু মেশিন লাগবে যেখানে ডেটা স্টোর করা থাকবে। এই মেশিনগুলোকে আমরা বলবো ডেটা নোড।

ছবির প্রতিটা ডেটা নোড একেকটা স্বতন্ত্র মেশিন। প্রতিটায় অপারেটিং সিস্টেম (সাধারণত লিনাক্স) ইনস্টল করা আছে, হার্ডডিস্ক, র্যাম আছে। এক্সেস পারমিশন থাকলে এবং আইপি অ্যাড্রেস জানা থাকলে তুমি ssh টুলস দিয়ে মেশিনগুলোতে এক্সেস করতে পারবে।
আমাদের বড় বড় ফাইলগুলো আমরা ভাগ ভাগ করে ডেটা নোডে স্টোর করবো। কিন্তু সমস্যা হলো কোন মেশিনে জায়গা ফাকা আছে, কোন ডেটা কোন মেশিনে আছে সেগুলো বলে দিবে কে? সে জন্য আমাদের একটা লিডার নোড লাগবে। লিডার নোড হলো এই পুরো ফাইল সিস্টেমের হর্তাকর্তা, সে ঠিক করে দিবে কোন ডেটা কোথায় রাখা হবে, কেউ ডেটা রিড করতে চাইলে সে বলে দিবে কোথায় ডেটা আছে।
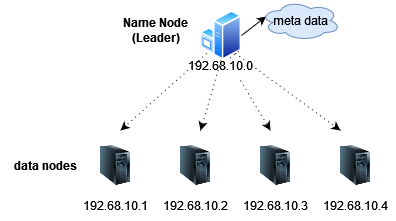
ডিস্ট্রিবিউটেড ফাইল সিস্টেমের কনটেক্সটে লিডার নোডের আরেকটা নাম হলো Name Node। নেম নোড বলার কারণ সম্ভবত লিডারের কাছে সব ডেটা নোডের নাম-ধাম জাতীয় তথ্য থাকে, তবে আমার কাছে লিডার নোড নামটাই বেশি পছন্দ। ডেটা সংক্রান্ত যেসব তথ্য লিডারের কাছে থাকে সেগুলো মেটা ডেটা বলা হয়। মেটা ডেটার সংজ্ঞা হলো “data that provides information about other data”, এক্ষেত্রে ফাইলের নাম, লোকেশন, রেপ্লিকার সংখ্যা এগুলো মেটা ডেটা। লিডার নোডের মেমরিতে সাধারণত ডেটাগুলো লোড করা থাকে।
এখন আমরা মোটামুটি একটা চলনসই ফাইল সিস্টেম পেয়ে গেলাম, কিন্তু ফাইল আপলোড বা রিড করবো কিভাবে? এধরণের অপারেশনের জন্য ক্লায়েন্ট একটা লাইব্রেরি ডাউনলোড করে নিতে হয়। সেই লাইব্রেরির দেয়ে এপিআই ব্যবহার করে ক্লায়েন্ট নিজেকে অথেন্টিকেট করে ফাইল আপলোড বা রিড করতে পারে।
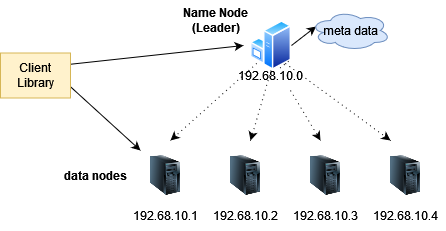
ফাইল আপলোড করার জন্য, রিড করার জন্য, ফোল্ডার ব্রাউজ করার জন্য ক্লায়েন্ট লাইব্রেরিতে ইন্টারফেস থাকে। রিড করার সময় ক্লায়েন্ট লাইব্রেরি নেম নোডের কাছে জেনে নেয় কোন ডেটা নোডে ফাইলটা আছে, তারপর সেই ডেটা নোডের সাথে যোগাযোগ করে ডেটা রিড করে। রিড করার সময় ক্লায়েন্টের মনে হবে সে একটা মেশিনে রাখা ডেটা পড়ছে, ডিস্ট্রিবিউশনের ব্যাপারগুলো ক্লায়েন্ট লাইব্রেরি আর নেমনোড মিলে হ্যান্ডেল করে। যেহেতু ফাইলগুলোর সাইজ অনেক বড়, তাই পার্শিয়াল ডেটা রিড করার অপশন থাকে।
ডেটা রাইট করার সময়ও একই প্রসেস। ইউজার ক্লায়েন্ট লাইব্রেরির ফাইল আপলোড ইন্টারফেস ব্যবহার করে। আপলোড ফাংশন নেম নোডের সাথে যোগযোগ করে জেনে নেয় কোন কোন ডেটা নোডে খালি জায়গা আছে। তারপর ফাইলটাকে একাধিক ব্লকে ভাগ করে একেক ব্লক একেক ডেটা নোডে পাঠিয়ে দেয়া হয়।
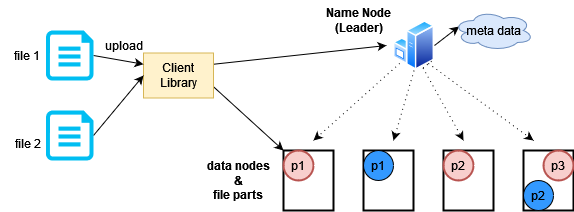
উপরের ছবিতে দেখা যাচ্ছে কিভাবে দুটো ফাইল ভাগ করে একাধিক ডেটা নোডে স্টোর করা হয়েছে।
এখন আমাদের সামনে নতুন একটা সমস্যা হাজির হয়েছে। কোনো একটা ডেটা নোড কিছু সময়ের জন্য ডাউন থাকলে কি হবে? সফটওয়্যার আপডেট, বৈদ্যুতিক গোলযোগ সহ বিভিন্ন কারণে এটা ঘটতে পারে। এটার সমাধান হলো প্রতিটা ডেটার প্রতিটা পার্টের একাধিক কপি করে ভিন্ন ভিন্ন ডেটা নোডে রাখে। একে বলা হয় রেপ্লিকেশন। এতে করে স্টোরেজ স্পেস কিছুটা বেশি লাগবে কিন্তু High Availability নিশ্চিত করা যাবে। বর্তমানে স্টোরেজ স্পেস স্বস্তা একটা জিনিস, তাই সেটা কোন সমস্যা না।
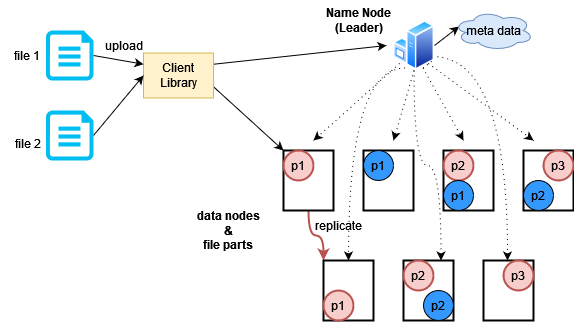
ছবিতে ফাইল প্রতিটা পার্টের ১টা করে অতিরিক্ত কপি করা হয়েছে। ক্লায়েন্ট চাইলে কনফিগারেশন ফাইলে আপডেট করে রেপ্লিকার সংখ্যা কম-বেশি করতে পারে তবে সাধারণত অন্তত ৩টা কপি স্টোর করা হয়। রেপ্লিকা তৈরির দায়িত্ব ডেটা নোডের, তবে লিডার বা নেম নোডই বলে দেয় কখন কোন ডেটা কোন নোডে কপি করতে হবে।
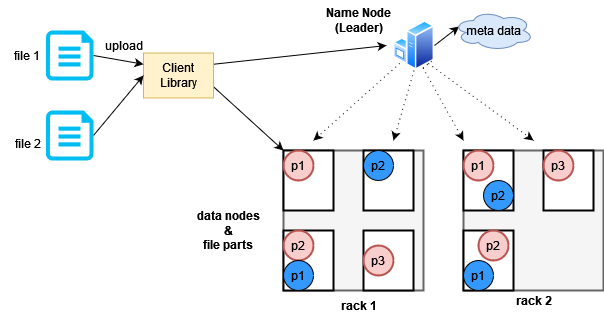
এখানে আরেকটা ইন্টারেস্টিং অপটিমাইজেশন আছে যেটাকে বলা হয় Rack Awareness। ডেটা সেন্টারে মেশিনগুলোকে বিভিন্ন র্যাকে সাজিয়ে রাখা হয়, নিচের ছবির মতো করে:

একই র্যাকের মেশিনগুলো সাধারণ একই কেবল শেয়ার করে বিভিন্ন ধরণের কানেকশনের জন্য। বৈদ্যুতিক গোলযোগ হলে একই র্যাকের সবগুলো মেশিন একসাথে বন্ধ হয়ে যাওয়ার সম্ভবনা থাকে। লিডার নোড যদি জানে যে কোন মেশিন কোন র্যাকে আছে তাহলে সে রেপ্লিকা তৈরির সময় কি করবে? বুদ্ধিমানের কাজ হলো একেকটা রেপ্লিকা একেকটা র্যাকে পাঠিয়ে দেয়া।
লিডার নোড কিভাবে জানবে কোন ডেটা নোড ডাউন হয়ে গেছে? লিডার কয়েক সেকেন্ড পরপর ডেটা নোড গুলোকে পিং করতে থাকে, আর ডেটা নোড সেটার উত্তর দিয়ে জানান দিতে থাকে যে সে বেঁচে আছে। এটাকে অনেক সময় হার্টবিট চেক করাও বলা হয়।
আরেকটা সিংগেল পয়েন্ট অফ ফেইলর রয়ে গেছে, সেটা হলো লিডার নোড। লিডার নোড ডাউন হলে কি ঘটবে? এটার একটা সমাধান হলো সেকেন্ডারি লিডার নোড ব্যবহার করা। সেকেন্ডারি লিডার চুপচাপ অবজার্ভ করবে লিডারকে, যেই দেখবে লিডার ডাউন হয়ে গেছে, সে তখন লিডারের দায়িত্ব নিয়ে নিবে। এই ফাকে লিডার রিকভার করলে আগের লিডার এখন সেকেন্ডারি পজিশনে চলে যাবে। প্রাইমারি আর সেকেন্ডারি দুইজনকেই কিন্তু মেটাডেটার কপি মেইনটেইন করতে হবে।
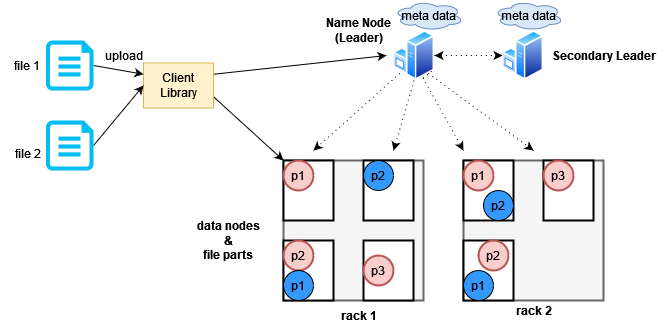
এখন তুমি প্রশ্ন করতে পারো দুটো লিডার নোডই ডাউন হয়ে গেলে কি হবে? আসলে ডিস্ট্রিবিউটেড সিস্টেমে একদম ১০০% ফেইলসেফ বলে কিছু নেই, তুমি চাইলে তৃতীয় লিডার যোগ করে রিলায়বিলিটি বাড়াতে পারো কিন্তু তাতেও কিন্তু সিস্টেম ডাউন হওয়ার সম্ভাবনা থেকেই যায়। আর তুমি যত নোড অ্যাড করবে তত তোমার সার্ভার বিল বাড়বে, মেইনটেনেন্সও জটিল হবে। ডেভওপস ইঞ্জিনিয়ারদের জন্য খরচ কম রেখে সাইটকে রিলায়েবল করা খুব বড় একটা চ্যালেঞ্জ।
আমি এতক্ষণ ডিস্ট্রিবিউটেড ফাইল সিস্টেমের যে আর্কিটেকচারটা দেখিয়েছি সেটা আমার কাল্পনিক কোন ডিজাইন না, এটা হলো Apache কোম্পানির তৈরি HADOOP Distributed File System বা সংক্ষেপে HDFS এর টপ-লেভেল আর্কিটেকচার। ডিস্ট্রিবিউটেড ফাইল সিস্টেমের ডেটা প্রসেসিং এর জন্য একটা টেকনিক আছে যেটার নাম ম্যাপ-রিডিউস। বিগ ডেটা প্রসেসিং এর একদম হ্যালো-ওয়ার্ল্ড হলো ম্যাপ-রিডিউস, গুগলের রিসার্চাররা সবার প্রথমে এই টেকনিক আবিষ্কার করেন, এটা নিয়ে একটা বিখ্যাত রিসার্চ পেপার আছে, তুমি ম্যাপ রিডিউস পেপার নামে সার্চ করলেই পাবে। Apache কোম্পানি HDFS এ রাখা ফাইলের উপর ম্যাপ-রিডিউস প্রয়োগ করার জন্য ইকোসিস্টেমও তৈরি করেছে, তাই HDFS খুবই জনপ্রিয়।
আমি কিছুদিন একটা বড় ইকমার্স কোম্পানি রিকমেন্ডেশন টিমে কাজ করেছি, সেখানে আমরা HDFS এ বিভিন্ন ইউজার ডেটা, সার্ভার লগ ইত্যাদি স্টোর করে পরে ম্যাপ-রিডিউস সহ আরো কিছু বিগডেটা প্রসেসিং টেকনিক ব্যবহার করে ব্যবহারকারিকে প্রোডাক্ট সাজেশন পাঠানো হতো। এভাবে ডেটা ভাগ করে রাখার কারণে অনেক বড় বড় ডেটা সেটের উপর মেশিন লার্নিং অ্যালগরিদম সহজেই চালানো যায়। প্রতিটা ডাটা নোডের ক্ষমতা আছে সেই নোডের ডেটার উপরে অ্যালগরিদম প্রয়োগ করার, সেজন্য ডেটা অন্য কোথাও সরানো দরকার হয় না।
আমার বর্ণনা করা আর্কিটেকচারই শেষ না, HDFS এ আরো অনেক জটিলতা আছে। যেমন বিভিন্ন ডেটা নোডের ডেটাগুলোকে কনসিস্টেন্ট রাখাটা একটা বড় চ্যালেঞ্জ, তুমি কিভাবে নিশ্চিত হতে পারো সবগুলো রেপ্লিকার ডেটা হুবুহু এক? এই কনসিস্টেন্সি মেইনটেইন করার জন্য প্যাক্সোস নামের একটা বেশ জটিল অ্যালগরিদম আছে, HDFS জুকিপার নামের একটা টুলস ব্যবহার করে সেটা ইমপ্লিমেন্ট করে, তুমি চাইলে বিস্তারিত ঘাটাঘাটি করতে পারো।
আজ এই পর্যন্তই, হ্যাপি কোডিং!
রেফারেন্স:
অফিসিয়াল ডকুমেন্টেশন
Design Data Intensive Application book

ফেসবুকে মন্তব্য
Powered by Facebook Comments